
После выравнивания получим функцию следующего вида: g (x) = x + 1 3 + 1 .
Мы можем аппроксимировать эти данные с помощью линейной зависимости y = a x + b , вычислив соответствующие параметры. Для этого нам нужно будет применить так называемый метод наименьших квадратов. Также потребуется сделать чертеж, чтобы проверить, какая линия будет лучше выравнивать экспериментальные данные.
Yandex.RTB R-A-339285-1
В чем именно заключается МНК (метод наименьших квадратов)
Главное, что нам нужно сделать, – это найти такие коэффициенты линейной зависимости, при которых значение функции двух переменных F (a , b) = ∑ i = 1 n (y i - (a x i + b)) 2 будет наименьшим. Иначе говоря, при определенных значениях a и b сумма квадратов отклонений представленных данных от получившейся прямой будет иметь минимальное значение. В этом и состоит смысл метода наименьших квадратов. Все, что нам надо сделать для решения примера – это найти экстремум функции двух переменных.
Как вывести формулы для вычисления коэффициентов
Для того чтобы вывести формулы для вычисления коэффициентов, нужно составить и решить систему уравнений с двумя переменными. Для этого мы вычисляем частные производные выражения F (a , b) = ∑ i = 1 n (y i - (a x i + b)) 2 по a и b и приравниваем их к 0 .
δ F (a , b) δ a = 0 δ F (a , b) δ b = 0 ⇔ - 2 ∑ i = 1 n (y i - (a x i + b)) x i = 0 - 2 ∑ i = 1 n (y i - (a x i + b)) = 0 ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + ∑ i = 1 n b = ∑ i = 1 n y i ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + n b = ∑ i = 1 n y i
Для решения системы уравнений можно использовать любые методы, например, подстановку или метод Крамера. В результате у нас должны получиться формулы, с помощью которых вычисляются коэффициенты по методу наименьших квадратов.
n ∑ i = 1 n x i y i - ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n - ∑ i = 1 n x i 2 b = ∑ i = 1 n y i - a ∑ i = 1 n x i n
Мы вычислили значения переменных, при который функция
F (a , b) = ∑ i = 1 n (y i - (a x i + b)) 2 примет минимальное значение. В третьем пункте мы докажем, почему оно является именно таким.
Это и есть применение метода наименьших квадратов на практике. Его формула, которая применяется для поиска параметра a , включает в себя ∑ i = 1 n x i , ∑ i = 1 n y i , ∑ i = 1 n x i y i , ∑ i = 1 n x i 2 , а также параметр
n – им обозначено количество экспериментальных данных. Советуем вам вычислять каждую сумму отдельно. Значение коэффициента b вычисляется сразу после a .
Обратимся вновь к исходному примеру.
Пример 1
Здесь у нас n равен пяти. Чтобы было удобнее вычислять нужные суммы, входящие в формулы коэффициентов, заполним таблицу.
| i = 1 | i = 2 | i = 3 | i = 4 | i = 5 | ∑ i = 1 5 | |
| x i | 0 | 1 | 2 | 4 | 5 | 12 |
| y i | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 | 12 , 9 |
| x i y i | 0 | 2 , 4 | 5 , 2 | 11 , 2 | 15 | 33 , 8 |
| x i 2 | 0 | 1 | 4 | 16 | 25 | 46 |
Решение
Четвертая строка включает в себя данные, полученные при умножении значений из второй строки на значения третьей для каждого отдельного i . Пятая строка содержит данные из второй, возведенные в квадрат. В последнем столбце приводятся суммы значений отдельных строчек.
Воспользуемся методом наименьших квадратов, чтобы вычислить нужные нам коэффициенты a и b . Для этого подставим нужные значения из последнего столбца и подсчитаем суммы:
n ∑ i = 1 n x i y i - ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n - ∑ i = 1 n x i 2 b = ∑ i = 1 n y i - a ∑ i = 1 n x i n ⇒ a = 5 · 33 , 8 - 12 · 12 , 9 5 · 46 - 12 2 b = 12 , 9 - a · 12 5 ⇒ a ≈ 0 , 165 b ≈ 2 , 184
У нас получилось, что нужная аппроксимирующая прямая будет выглядеть как y = 0 , 165 x + 2 , 184 . Теперь нам надо определить, какая линия будет лучше аппроксимировать данные – g (x) = x + 1 3 + 1 или 0 , 165 x + 2 , 184 . Произведем оценку с помощью метода наименьших квадратов.
Чтобы вычислить погрешность, нам надо найти суммы квадратов отклонений данных от прямых σ 1 = ∑ i = 1 n (y i - (a x i + b i)) 2 и σ 2 = ∑ i = 1 n (y i - g (x i)) 2 , минимальное значение будет соответствовать более подходящей линии.
σ 1 = ∑ i = 1 n (y i - (a x i + b i)) 2 = = ∑ i = 1 5 (y i - (0 , 165 x i + 2 , 184)) 2 ≈ 0 , 019 σ 2 = ∑ i = 1 n (y i - g (x i)) 2 = = ∑ i = 1 5 (y i - (x i + 1 3 + 1)) 2 ≈ 0 , 096
Ответ:
поскольку σ 1 < σ 2 , то прямой, наилучшим образом аппроксимирующей исходные данные, будет
y = 0 , 165 x + 2 , 184 .
Метод наименьших квадратов наглядно показан на графической иллюстрации. С помощью красной линии отмечена прямая g (x) = x + 1 3 + 1 , синей – y = 0 , 165 x + 2 , 184 . Исходные данные обозначены розовыми точками.
Поясним, для чего именно нужны приближения подобного вида.
Они могут быть использованы в задачах, требующих сглаживания данных, а также в тех, где данные надо интерполировать или экстраполировать. Например, в задаче, разобранной выше, можно было бы найти значение наблюдаемой величины y при x = 3 или при x = 6 . Таким примерам мы посвятили отдельную статью.
Доказательство метода МНК
Чтобы функция приняла минимальное значение при вычисленных a и b , нужно, чтобы в данной точке матрица квадратичной формы дифференциала функции вида F (a , b) = ∑ i = 1 n (y i - (a x i + b)) 2 была положительно определенной. Покажем, как это должно выглядеть.
Пример 2
У нас есть дифференциал второго порядка следующего вида:
d 2 F (a ; b) = δ 2 F (a ; b) δ a 2 d 2 a + 2 δ 2 F (a ; b) δ a δ b d a d b + δ 2 F (a ; b) δ b 2 d 2 b
Решение
δ 2 F (a ; b) δ a 2 = δ δ F (a ; b) δ a δ a = = δ - 2 ∑ i = 1 n (y i - (a x i + b)) x i δ a = 2 ∑ i = 1 n (x i) 2 δ 2 F (a ; b) δ a δ b = δ δ F (a ; b) δ a δ b = = δ - 2 ∑ i = 1 n (y i - (a x i + b)) x i δ b = 2 ∑ i = 1 n x i δ 2 F (a ; b) δ b 2 = δ δ F (a ; b) δ b δ b = δ - 2 ∑ i = 1 n (y i - (a x i + b)) δ b = 2 ∑ i = 1 n (1) = 2 n
Иначе говоря, можно записать так: d 2 F (a ; b) = 2 ∑ i = 1 n (x i) 2 d 2 a + 2 · 2 ∑ x i i = 1 n d a d b + (2 n) d 2 b .
Мы получили матрицу квадратичной формы вида M = 2 ∑ i = 1 n (x i) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n .
В этом случае значения отдельных элементов не будут меняться в зависимости от a и b . Является ли эта матрица положительно определенной? Чтобы ответить на этот вопрос, проверим, являются ли ее угловые миноры положительными.
Вычисляем угловой минор первого порядка: 2 ∑ i = 1 n (x i) 2 > 0 . Поскольку точки x i не совпадают, то неравенство является строгим. Будем иметь это в виду при дальнейших расчетах.
Вычисляем угловой минор второго порядка:
d e t (M) = 2 ∑ i = 1 n (x i) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n = 4 n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2
После этого переходим к доказательству неравенства n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 > 0 с помощью математической индукции.
- Проверим, будет ли данное неравенство справедливым при произвольном n . Возьмем 2 и подсчитаем:
2 ∑ i = 1 2 (x i) 2 - ∑ i = 1 2 x i 2 = 2 x 1 2 + x 2 2 - x 1 + x 2 2 = = x 1 2 - 2 x 1 x 2 + x 2 2 = x 1 + x 2 2 > 0
У нас получилось верное равенство (если значения x 1 и x 2 не будут совпадать).
- Сделаем предположение, что данное неравенство будет верным для n , т.е. n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 > 0 – справедливо.
- Теперь докажем справедливость при n + 1 , т.е. что (n + 1) ∑ i = 1 n + 1 (x i) 2 - ∑ i = 1 n + 1 x i 2 > 0 , если верно n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 > 0 .
Вычисляем:
(n + 1) ∑ i = 1 n + 1 (x i) 2 - ∑ i = 1 n + 1 x i 2 = = (n + 1) ∑ i = 1 n (x i) 2 + x n + 1 2 - ∑ i = 1 n x i + x n + 1 2 = = n ∑ i = 1 n (x i) 2 + n · x n + 1 2 + ∑ i = 1 n (x i) 2 + x n + 1 2 - - ∑ i = 1 n x i 2 + 2 x n + 1 ∑ i = 1 n x i + x n + 1 2 = = ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 + n · x n + 1 2 - x n + 1 ∑ i = 1 n x i + ∑ i = 1 n (x i) 2 = = ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 + x n + 1 2 - 2 x n + 1 x 1 + x 1 2 + + x n + 1 2 - 2 x n + 1 x 2 + x 2 2 + . . . + x n + 1 2 - 2 x n + 1 x 1 + x n 2 = = n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 + + (x n + 1 - x 1) 2 + (x n + 1 - x 2) 2 + . . . + (x n - 1 - x n) 2 > 0
Выражение, заключенное в фигурные скобки, будет больше 0 (исходя из того, что мы предполагали в пункте 2), и остальные слагаемые будут больше 0 , поскольку все они являются квадратами чисел. Мы доказали неравенство.
Ответ: найденные a и b будут соответствовать наименьшему значению функции F (a , b) = ∑ i = 1 n (y i - (a x i + b)) 2 , значит, они являются искомыми параметрами метода наименьших квадратов (МНК).
Если вы заметили ошибку в тексте, пожалуйста, выделите её и нажмите Ctrl+Enter
100 р бонус за первый заказ
Выберите тип работы Дипломная работа Курсовая работа Реферат Магистерская диссертация Отчёт по практике Статья Доклад Рецензия Контрольная работа Монография Решение задач Бизнес-план Ответы на вопросы Творческая работа Эссе Чертёж Сочинения Перевод Презентации Набор текста Другое Повышение уникальности текста Кандидатская диссертация Лабораторная работа Помощь on-line
Узнать цену
Метод наименьших квадратов - математический (математико-статистический) прием, служащий для выравнивания динамических рядов, выявления формыкорреляционной связи между случайными величинами и др. Состоит в том, что функция, описывающая данное явление, аппроксимируется более простой функцией. Причем последняя подбирается с таким расчетом, чтобы среднеквадратичное отклонение (см.Дисперсия) фактических уровней функции в наблюдаемых точках от выровненных было наименьшим.
Напр., по имеющимся данным (xi ,yi ) (i = 1, 2, ..., n ) строится такая кривая y = a + bx , на которой достигается минимум суммы квадратов отклонений
т. е. минимизируется функция, зависящая от двух параметров: a - отрезок на оси ординат и b - наклон прямой.
Уравнения, дающие необходимые условия минимизации функции S (a ,b ), называются нормальными уравнениями. В качестве аппроксимирующих функций применяются не только линейная (выравнивание по прямой линии), но и квадратическая, параболическая, экспоненциальная и др. Пример выравнивания динамического ряда по прямой см. на рис. M.2, где сумма квадратов расстояний (y 1 – ȳ 1)2 + (y 2 – ȳ 2)2 .... - наименьшая, и получившаяся прямая наилучшим образом отражает тенденцию динамического ряда наблюдений за некоторым показателем во времени.
Для несмещенности МНК-оценок необходимо и достаточно выполнения важнейшего условия регрессионного анализа: условное по факторам математическое ожидание случайной ошибки должно быть равно нулю. Данное условие, в частности, выполнено, если: 1.математическое ожидание случайных ошибок равно нулю, и 2.факторы и случайные ошибки - независимые случайные величины. Первое условие можно считать выполненным всегда для моделей с константой, так как константа берёт на себя ненулевое математическое ожидание ошибок. Второе условие - условие экзогенности факторов - принципиальное. Если это свойство не выполнено, то можно считать, что практически любые оценки будут крайне неудовлетворительными: они не будут даже состоятельными (то есть даже очень большой объём данных не позволяет получить качественные оценки в этом случае).
Наиболее распространенным в практике статистического оценивания параметров уравнений регрессии является метод наименьших квадратов. Этот метод основан на ряде предпосылок относительно природы данных и результатов построения модели. Основные из них - это четкое разделение исходных переменных на зависимые и независимые, некоррелированность факторов, входящих в уравнения, линейность связи, отсутствие автокорреляции остатков, равенство их математических ожиданий нулю и постоянная дисперсия.
Одной из основных гипотез МНК является предположение о равенстве дисперсий отклонений еi, т.е. их разброс вокруг среднего (нулевого) значения ряда должен быть величиной стабильной. Это свойство называется гомоскедастичностью. На практике дисперсии отклонений достаточно часто неодинаковы, то есть наблюдается гетероскедастичность. Это может быть следствием разных причин. Например, возможны ошибки в исходных данных. Случайные неточности в исходной информации, такие как ошибки в порядке чисел, могут оказать ощутимое влияние на результаты. Часто больший разброс отклонений єi, наблюдается при больших значениях зависимой переменной (переменных). Если в данных содержится значительная ошибка, то, естественно, большим будет и отклонение модельного значения, рассчитанного по ошибочным данным. Для того, чтобы избавиться от этой ошибки нам нужно уменьшить вклад этих данных в результаты расчетов, задать для них меньший вес, чем для всех остальных. Эта идея реализована во взвешенном МНК.
Которое находит самое широкое применение в различных областях науки и практической деятельности. Это может быть физика, химия, биология, экономика, социология, психология и так далее, так далее. Волею судьбы мне часто приходится иметь дело с экономикой, и поэтому сегодня я оформлю вам путёвку в удивительную страну под названием Эконометрика =) …Как это не хотите?! Там очень хорошо – нужно только решиться! …Но вот то, что вы, наверное, определённо хотите – так это научиться решать задачи методом наименьших квадратов . И особо прилежные читатели научатся решать их не только безошибочно, но ещё и ОЧЕНЬ БЫСТРО;-) Но сначала общая постановка задачи + сопутствующий пример:
Пусть в некоторой предметной области исследуются показатели , которые имеют количественное выражение. При этом есть все основания полагать, что показатель зависит от показателя . Это полагание может быть как научной гипотезой, так и основываться на элементарном здравом смысле. Оставим, однако, науку в сторонке и исследуем более аппетитные области – а именно, продовольственные магазины. Обозначим через:
– торговую площадь продовольственного магазина, кв.м.,
– годовой товарооборот продовольственного магазина, млн. руб.
Совершенно понятно, что чем больше площадь магазина, тем в большинстве случаев будет больше его товарооборот.
Предположим, что после проведения наблюдений/опытов/подсчётов/танцев с бубном в нашем распоряжении оказываются числовые данные:
С гастрономами, думаю, всё понятно: – это площадь 1-го магазина, – его годовой товарооборот, – площадь 2-го магазина, – его годовой товарооборот и т.д. Кстати, совсем не обязательно иметь доступ к секретным материалам – довольно точную оценку товарооборота можно получить средствами математической статистики
. Впрочем, не отвлекаемся, курс коммерческого шпионажа – он уже платный =)
Табличные данные также можно записать в виде точек и изобразить в привычной для нас декартовой системе .
Ответим на важный вопрос: сколько точек нужно для качественного исследования?
Чем больше, тем лучше. Минимально допустимый набор состоит из 5-6 точек. Кроме того, при небольшом количестве данных в выборку нельзя включать «аномальные» результаты. Так, например, небольшой элитный магазин может выручать на порядки больше «своих коллег», искажая тем самым общую закономерность, которую и требуется найти!
Если совсем просто – нам нужно подобрать функцию , график
которой проходит как можно ближе к точкам ![]() . Такую функцию называют аппроксимирующей
(аппроксимация – приближение)
или теоретической функцией
. Вообще говоря, тут сразу появляется очевидный «претендент» – многочлен высокой степени, график которого проходит через ВСЕ точки. Но этот вариант сложен, а зачастую и просто некорректен (т.к. график будет всё время «петлять» и плохо отражать главную тенденцию)
.
. Такую функцию называют аппроксимирующей
(аппроксимация – приближение)
или теоретической функцией
. Вообще говоря, тут сразу появляется очевидный «претендент» – многочлен высокой степени, график которого проходит через ВСЕ точки. Но этот вариант сложен, а зачастую и просто некорректен (т.к. график будет всё время «петлять» и плохо отражать главную тенденцию)
.
Таким образом, разыскиваемая функция должна быть достаточно простА и в то же время отражать зависимость адекватно. Как вы догадываетесь, один из методов нахождения таких функций и называется методом наименьших квадратов
. Сначала разберём его суть в общем виде. Пусть некоторая функция приближает экспериментальные данные :
Как оценить точность данного приближения? Вычислим и разности (отклонения) между экспериментальными и функциональными значениями (изучаем чертёж)
. Первая мысль, которая приходит в голову – это оценить, насколько великА сумма , но проблема состоит в том, что разности могут быть и отрицательны (например, ![]() )
и отклонения в результате такого суммирования будут взаимоуничтожаться. Поэтому в качестве оценки точности приближения напрашивается принять сумму модулей
отклонений:
)
и отклонения в результате такого суммирования будут взаимоуничтожаться. Поэтому в качестве оценки точности приближения напрашивается принять сумму модулей
отклонений:
![]() или в свёрнутом виде: (вдруг кто не знает: – это значок суммы, а – вспомогательная переменная-«счётчик», которая принимает значения от 1 до )
.
или в свёрнутом виде: (вдруг кто не знает: – это значок суммы, а – вспомогательная переменная-«счётчик», которая принимает значения от 1 до )
.
Приближая экспериментальные точки различными функциями, мы будем получать разные значения , и очевидно, где эта сумма меньше – та функция и точнее.
Такой метод существует и называется он методом наименьших модулей . Однако на практике получил гораздо бОльшее распространение метод наименьших квадратов , в котором возможные отрицательные значения ликвидируются не модулем, а возведением отклонений в квадрат:
![]() , после чего усилия направлены на подбор такой функции , чтобы сумма квадратов отклонений
, после чего усилия направлены на подбор такой функции , чтобы сумма квадратов отклонений ![]() была как можно меньше. Собственно, отсюда и название метода.
была как можно меньше. Собственно, отсюда и название метода.
И сейчас мы возвращаемся к другому важному моменту: как отмечалось выше, подбираемая функция должна быть достаточно простА – но ведь и таких функций тоже немало: линейная , гиперболическая , экспоненциальная , логарифмическая , квадратичная и т.д. И, конечно же, тут сразу бы хотелось «сократить поле деятельности». Какой класс функций выбрать для исследования? Примитивный, но эффективный приём:
– Проще всего изобразить точки ![]() на чертеже и проанализировать их расположение. Если они имеют тенденцию располагаться по прямой, то следует искать уравнение прямой
на чертеже и проанализировать их расположение. Если они имеют тенденцию располагаться по прямой, то следует искать уравнение прямой
![]() с оптимальными значениями и . Иными словами, задача состоит в нахождении ТАКИХ коэффициентов – чтобы сумма квадратов отклонений была наименьшей.
с оптимальными значениями и . Иными словами, задача состоит в нахождении ТАКИХ коэффициентов – чтобы сумма квадратов отклонений была наименьшей.
Если же точки расположены, например, по гиперболе
, то заведомо понятно, что линейная функция будет давать плохое приближение. В этом случае ищем наиболее «выгодные» коэффициенты для уравнения гиперболы ![]() – те, которые дают минимальную сумму квадратов
– те, которые дают минимальную сумму квадратов  .
.
А теперь обратите внимание, что в обоих случаях речь идёт о функции двух переменных
, аргументами которой являются параметры разыскиваемых зависимостей
:
И по существу нам требуется решить стандартную задачу – найти минимум функции двух переменных .
Вспомним про наш пример: предположим, что «магазинные» точки имеют тенденцию располагаться по прямой линии и есть все основания полагать наличие линейной зависимости
товарооборота от торговой площади. Найдём ТАКИЕ коэффициенты «а» и «бэ», чтобы сумма квадратов отклонений ![]() была наименьшей. Всё как обычно – сначала частные производные 1-го порядка
. Согласно правилу линейности
дифференцировать можно прямо под значком суммы:
была наименьшей. Всё как обычно – сначала частные производные 1-го порядка
. Согласно правилу линейности
дифференцировать можно прямо под значком суммы:
Если хотите использовать данную информацию для реферата или курсовика – буду очень благодарен за поставленную ссылку в списке источников, такие подробные выкладки найдёте мало где:
Составим стандартную систему:
Сокращаем каждое уравнение на «двойку» и, кроме того, «разваливаем» суммы:
Примечание
: самостоятельно проанализируйте, почему «а» и «бэ» можно вынести за значок суммы. Кстати, формально это можно проделать и с суммой
![]()
Перепишем систему в «прикладном» виде:
после чего начинает прорисовываться алгоритм решения нашей задачи:
Координаты точек мы знаем? Знаем. Суммы ![]() найти можем? Легко. Составляем простейшую систему двух линейных уравнений с двумя неизвестными
(«а» и «бэ»). Систему решаем, например, методом Крамера
, в результате чего получаем стационарную точку . Проверяя достаточное условие экстремума
, можно убедиться, что в данной точке функция
найти можем? Легко. Составляем простейшую систему двух линейных уравнений с двумя неизвестными
(«а» и «бэ»). Систему решаем, например, методом Крамера
, в результате чего получаем стационарную точку . Проверяя достаточное условие экстремума
, можно убедиться, что в данной точке функция ![]() достигает именно минимума
. Проверка сопряжена с дополнительными выкладками и поэтому оставим её за кадром (при необходимости недостающий кадр можно посмотреть )
. Делаем окончательный вывод:
достигает именно минимума
. Проверка сопряжена с дополнительными выкладками и поэтому оставим её за кадром (при необходимости недостающий кадр можно посмотреть )
. Делаем окончательный вывод:
Функция ![]() наилучшим образом (по крайне мере, по сравнению с любой другой линейной функцией)
приближает экспериментальные точки
наилучшим образом (по крайне мере, по сравнению с любой другой линейной функцией)
приближает экспериментальные точки ![]() . Грубо говоря, её график проходит максимально близко к этим точкам. В традициях эконометрики
полученную аппроксимирующую функцию также называют уравнением пАрной линейной регрессии
.
. Грубо говоря, её график проходит максимально близко к этим точкам. В традициях эконометрики
полученную аппроксимирующую функцию также называют уравнением пАрной линейной регрессии
.
Рассматриваемая задача имеет большое практическое значение. В ситуации с нашим примером, уравнение ![]() позволяет прогнозировать, какой товарооборот («игрек»)
будет у магазина при том или ином значении торговой площади (том или ином значении «икс»)
. Да, полученный прогноз будет лишь прогнозом, но во многих случаях он окажется достаточно точным.
позволяет прогнозировать, какой товарооборот («игрек»)
будет у магазина при том или ином значении торговой площади (том или ином значении «икс»)
. Да, полученный прогноз будет лишь прогнозом, но во многих случаях он окажется достаточно точным.
Я разберу всего лишь одну задачу с «реальными» числами, поскольку никаких трудностей в ней нет – все вычисления на уровне школьной программы 7-8 класса. В 95 процентов случаев вам будет предложено отыскать как раз линейную функцию, но в самом конце статьи я покажу, что ничуть не сложнее отыскать уравнения оптимальной гиперболы, экспоненты и некоторых других функций.
По сути, осталось раздать обещанные плюшки – чтобы вы научились решать такие примеры не только безошибочно, но ещё и быстро. Внимательно изучаем стандарт:
Задача
В результате исследования взаимосвязи двух показателей, получены следующие пары чисел:
Методом наименьших квадратов найти линейную функцию, которая наилучшим образом приближает эмпирические (опытные)
данные. Сделать чертеж, на котором в декартовой прямоугольной системе координат построить экспериментальные точки и график аппроксимирующей функции ![]() . Найти сумму квадратов отклонений между эмпирическими и теоретическими значениями. Выяснить, будет ли функция лучше (с точки зрения метода наименьших квадратов)
приближать экспериментальные точки.
. Найти сумму квадратов отклонений между эмпирическими и теоретическими значениями. Выяснить, будет ли функция лучше (с точки зрения метода наименьших квадратов)
приближать экспериментальные точки.
Заметьте, что «иксовые» значения – натуральные, и это имеет характерный содержательный смысл, о котором я расскажу чуть позже; но они, разумеется, могут быть и дробными. Кроме того, в зависимости от содержания той или иной задачи как «иксовые», так и «игрековые» значения полностью или частично могут быть отрицательными. Ну а у нас дана «безликая» задача, и мы начинаем её решение :
Коэффициенты оптимальной функции найдём как решение системы:
В целях более компактной записи переменную-«счётчик» можно опустить, поскольку и так понятно, что суммирование осуществляется от 1 до .
Расчёт нужных сумм удобнее оформить в табличном виде:
Вычисления можно провести на микрокалькуляторе, но гораздо лучше использовать Эксель – и быстрее, и без ошибок; смотрим короткий видеоролик:
Таким образом, получаем следующую систему
:![]()
Тут можно умножить второе уравнение на 3 и из 1-го уравнения почленно вычесть 2-е
. Но это везение – на практике системы чаще не подарочны, и в таких случаях спасает метод Крамера
:
, значит, система имеет единственное решение.

Выполним проверку. Понимаю, что не хочется, но зачем же пропускать ошибки там, где их можно стопроцентно не пропустить? Подставим найденное решение в левую часть каждого уравнения системы:
Получены правые части соответствующих уравнений, значит, система решена правильно.
Таким образом, искомая аппроксимирующая функция: – из всех линейных функций экспериментальные данные наилучшим образом приближает именно она.
В отличие от прямой
зависимости товарооборота магазина от его площади, найденная зависимость является обратной
(принцип «чем больше – тем меньше»)
, и этот факт сразу выявляется по отрицательному угловому коэффициенту
. Функция ![]() сообщает нам о том, что с увеличение некоего показателя на 1 единицу значение зависимого показателя уменьшается в среднем
на 0,65 единиц. Как говорится, чем выше цена на гречку, тем меньше её продано.
сообщает нам о том, что с увеличение некоего показателя на 1 единицу значение зависимого показателя уменьшается в среднем
на 0,65 единиц. Как говорится, чем выше цена на гречку, тем меньше её продано.
Для построения графика аппроксимирующей функции найдём два её значения:
и выполним чертёж:
Построенная прямая называется линией тренда
(а именно – линией линейного тренда, т.е. в общем случае тренд – это не обязательно прямая линия)
. Всем знакомо выражение «быть в тренде», и, думаю, что этот термин не нуждается в дополнительных комментариях.
Вычислим сумму квадратов отклонений ![]() между эмпирическими и теоретическими значениями. Геометрически – это сумма квадратов длин «малиновых» отрезков (два из которых настолько малы, что их даже не видно)
.
между эмпирическими и теоретическими значениями. Геометрически – это сумма квадратов длин «малиновых» отрезков (два из которых настолько малы, что их даже не видно)
.
Вычисления сведём в таблицу:
Их можно опять же провести вручную, на всякий случай приведу пример для 1-й точки:![]()
но намного эффективнее поступить уже известным образом:
Еще раз повторим: в чём смысл полученного результата?
Из всех линейных функций
у функции ![]() показатель является наименьшим, то есть в своём семействе это наилучшее приближение. И здесь, кстати, не случаен заключительный вопрос задачи: а вдруг предложенная экспоненциальная функция
показатель является наименьшим, то есть в своём семействе это наилучшее приближение. И здесь, кстати, не случаен заключительный вопрос задачи: а вдруг предложенная экспоненциальная функция ![]() будет лучше приближать экспериментальные точки?
будет лучше приближать экспериментальные точки?
Найдем соответствующую сумму квадратов отклонений – чтобы различать, я обозначу их буквой «эпсилон». Техника точно такая же:
И снова на всякий пожарный вычисления для 1-й точки:
В Экселе пользуемся стандартной функцией EXP
(синтаксис можно посмотреть в экселевской Справке)
.
Вывод
: , значит, экспоненциальная функция приближает экспериментальные точки хуже, чем прямая ![]() .
.
Но тут следует отметить, что «хуже» – это ещё не значит
, что плохо. Сейчас построил график этой экспоненциальной функции – и он тоже проходит близко к точкам ![]() – да так, что без аналитического исследования и сказать трудно, какая функция точнее.
– да так, что без аналитического исследования и сказать трудно, какая функция точнее.
На этом решение закончено, и я возвращаюсь к вопросу о натуральных значениях аргумента. В различных исследованиях, как правило, экономических или социологических, натуральными «иксами» нумеруют месяцы, годы или иные равные временнЫе промежутки. Рассмотрим, например, такую задачу.
- Tutorial
Введение
Я математик-программист. Самый большой скачок в своей карьере я совершил, когда научился говорить:«Я ничего не понимаю!» Сейчас мне не стыдно сказать светилу науки, что мне читает лекцию, что я не понимаю, о чём оно, светило, мне говорит. И это очень сложно. Да, признаться в своём неведении сложно и стыдно. Кому понравится признаваться в том, что он не знает азов чего-то-там. В силу своей профессии я должен присутствовать на большом количестве презентаций и лекций, где, признаюсь, в подавляющем большинстве случаев мне хочется спать, потому что я ничего не понимаю. А не понимаю я потому, что огромная проблема текущей ситуации в науке кроется в математике. Она предполагает, что все слушатели знакомы с абсолютно всеми областями математики (что абсурдно). Признаться в том, что вы не знаете, что такое производная (о том, что это - чуть позже) - стыдно.
Но я научился говорить, что я не знаю, что такое умножение. Да, я не знаю, что такое подалгебра над алгеброй Ли. Да, я не знаю, зачем нужны в жизни квадратные уравнения. К слову, если вы уверены, что вы знаете, то нам есть над чем поговорить! Математика - это серия фокусов. Математики стараются запутать и запугать публику; там, где нет замешательства, нет репутации, нет авторитета. Да, это престижно говорить как можно более абстрактным языком, что есть по себе полная чушь.
Знаете ли вы, что такое производная? Вероятнее всего вы мне скажете про предел разностного отношения. На первом курсе матмеха СПбГУ Виктор Петрович Хавин мне определил
производную как коэффициент первого члена ряда Тейлора функции в точке (это была отдельная гимнастика, чтобы определить ряд Тейлора без производных). Я долго смеялся над таким определением, покуда в итоге не понял, о чём оно. Производная не что иное, как просто мера того, насколько функция, которую мы дифференцируем, похожа на функцию y=x, y=x^2, y=x^3.
Я сейчас имею честь читать лекции студентам, которые боятся математики. Если вы боитесь математики - нам с вами по пути. Как только вы пытаетесь прочитать какой-то текст, и вам кажется, что он чрезмерно сложен, то знайте, что он хреново написан. Я утверждаю, что нет ни одной области математики, о которой нельзя говорить «на пальцах», не теряя при этом точности.
Задача на ближайшее время: я поручил своим студентам понять, что такое линейно-квадратичный регулятор . Не постесняйтесь, потратьте три минуты своей жизни, сходите по ссылке. Если вы ничего не поняли, то нам с вами по пути. Я (профессиональный математик-программист) тоже ничего не понял. И я уверяю, в этом можно разобраться «на пальцах». На данный момент я не знаю, что это такое, но я уверяю, что мы сумеем разобраться.
Итак, первая лекция, которую я собираюсь прочитать своим студентам после того, как они в ужасе прибегут ко мне со словами, что линейно-квадратичный регулятор - это страшная бяка, которую никогда в жизни не осилить, это методы наименьших квадратов . Умеете ли вы решать линейные уравнения? Если вы читаете этот текст, то скорее всего нет.
Итак, даны две точки (x0, y0), (x1, y1), например, (1,1) и (3,2), задача найти уравнение прямой, проходящей через эти две точки:
иллюстрация

Эта прямая должна иметь уравнение типа следующего:
Здесь альфа и бета нам неизвестны, но известны две точки этой прямой:
Можно записать это уравнение в матричном виде:
Тут следует сделать лирическое отступление: что такое матрица? Матрица это не что иное, как двумерный массив. Это способ хранения данных, более никаких значений ему придавать не стоит. Это зависит от нас, как именно интерпретировать некую матрицу. Периодически я буду её интерпретировать как линейное отображение, периодически как квадратичную форму, а ещё иногда просто как набор векторов. Это всё будет уточнено в контексте.
Давайте заменим конкретные матрицы на их символьное представление:
Тогда (alpha, beta) может быть легко найдено:
Более конкретно для наших предыдущих данных:
Что ведёт к следующему уравнению прямой, проходящей через точки (1,1) и (3,2):
Окей, тут всё понятно. А давайте найдём уравнение прямой, проходящей через три точки: (x0,y0), (x1,y1) и (x2,y2):
Ой-ой-ой, а ведь у нас три уравнения на две неизвестных! Стандартный математик скажет, что решения не существует. А что скажет программист? А он для начала перепишет предыдующую систему уравнений в следующем виде:
В нашем случае векторы i,j,b трёхмерны, следовательно, (в общем случае) решения этой системы не существует. Любой вектор (alpha\*i + beta\*j) лежит в плоскости, натянутой на векторы (i, j). Если b не принадлежит этой плоскости, то решения не существует (равенства в уравнении не достичь). Что делать? Давайте искать компромисс. Давайте обозначим через e(alpha, beta) насколько именно мы не достигли равенства:
И будем стараться минимизировать эту ошибку:
Почему квадрат?
Мы ищем не просто минимум нормы, а минимум квадрата нормы. Почему? Сама точка минимума совпадает, а квадрат даёт гладкую функцию (квадратичную функцию от агрументов (alpha,beta)), в то время как просто длина даёт функцию в виде конуса, недифференцируемую в точке минимума. Брр. Квадрат удобнее.
Очевидно, что ошибка минимизируется, когда вектор e ортогонален плоскости, натянутой на векторы i и j .
Иллюстрация

Иными словами: мы ищем такую прямую, что сумма квадратов длин расстояний от всех точек до этой прямой минимальна:
UPDATE: тут у меня косяк, расстояние до прямой должно измеряться по вертикали, а не ортогональной проекцией. Вот этот комментатор прав.
Иллюстрация

Совсеми иными словами (осторожно, плохо формализовано, но на пальцах должно быть ясно): мы берём все возможные прямые между всеми парами точек и ищем среднюю прямую между всеми:
Иллюстрация

Иное объяснение на пальцах: мы прикрепляем пружинку между всеми точками данных (тут у нас три) и прямой, что мы ищем, и прямая равновесного состояния есть именно то, что мы ищем.
Минимум квадратичной формы
Итак, имея данный вектор b и плоскость, натянутую на столбцы-векторы матрицы A (в данном случае (x0,x1,x2) и (1,1,1)), мы ищем вектор e с минимум квадрата длины. Очевидно, что минимум достижим только для вектора e , ортогонального плоскости, натянутой на столбцы-векторы матрицы A :Иначе говоря, мы ищем такой вектор x=(alpha, beta), что:
Напоминаю, что этот вектор x=(alpha, beta) является минимумом квадратичной функции ||e(alpha, beta)||^2:
Тут нелишним будет вспомнить, что матрицу можно интерпретирвать в том числе как и квадратичную форму, например, единичная матрица ((1,0),(0,1)) может быть интерпретирована как функция x^2 + y^2:
квадратичная форма

Вся эта гимнастика известна под именем линейной регрессии .
Уравнение Лапласа с граничным условием Дирихле
Теперь простейшая реальная задача: имеется некая триангулированная поверхность, необходимо её сгладить. Например, давайте загрузим модель моего лица:
Изначальный коммит доступен . Для минимизации внешних зависимостей я взял код своего софтверного рендерера, уже на хабре. Для решения линейной системы я пользуюсь OpenNL , это отличный солвер, который, правда, очень сложно установить: нужно скопировать два файла (.h+.c) в папку с вашим проектом. Всё сглаживание делается следующим кодом:
For (int d=0; d<3; d++) {
nlNewContext();
nlSolverParameteri(NL_NB_VARIABLES, verts.size());
nlSolverParameteri(NL_LEAST_SQUARES, NL_TRUE);
nlBegin(NL_SYSTEM);
nlBegin(NL_MATRIX);
for (int i=0; i<(int)verts.size(); i++) {
nlBegin(NL_ROW);
nlCoefficient(i, 1);
nlRightHandSide(verts[i][d]);
nlEnd(NL_ROW);
}
for (unsigned int i=0; i
X, Y и Z координаты отделимы, я их сглаживаю по отдельности. То есть, я решаю три системы линейных уравнений, каждое имеет количество переменных равным количеству вершин в моей модели. Первые n строк матрицы A имеют только одну единицу на строку, а первые n строк вектора b имеют оригинальные координаты модели. То есть, я привязываю по пружинке между новым положением вершины и старым положением вершины - новые не должны слишком далеко уходить от старых.
Все последующие строки матрицы A (faces.size()*3 = количеству рёбер всех треугольников в сетке) имеют одно вхождение 1 и одно вхождение -1, причём вектор b имеет нулевые компоненты напротив. Это значит, я вешаю пружинку на каждое ребро нашей треугольной сетки: все рёбра стараются получить одну и ту же вершину в качестве отправной и финальной точки.
Ещё раз: переменными являются все вершины, причём они не могут далеко отходить от изначального положения, но при этом стараются стать похожими друг на друга.
Вот результат:

Всё бы было хорошо, модель действительно сглажена, но она отошла от своего изначального края. Давайте чуть-чуть изменим код:
For (int i=0; i<(int)verts.size(); i++) { float scale = border[i] ? 1000: 1; nlBegin(NL_ROW); nlCoefficient(i, scale); nlRightHandSide(scale*verts[i][d]); nlEnd(NL_ROW); }
В нашей матрице A я для вершин, что находятся на краю, добавляю не строку из разряда v_i = verts[i][d], а 1000*v_i = 1000*verts[i][d]. Что это меняет? А меняет это нашу квадратичную форму ошибки. Теперь единичное отклонение от вершины на краю будет стоить не одну единицу, как раньше, а 1000*1000 единиц. То есть, мы повесили более сильную пружинку на крайние вершины, решение предпочтёт сильнее растянуть другие. Вот результат:

Давайте вдвое усилим пружинки между вершинами:
nlCoefficient(face[ j ], 2);
nlCoefficient(face[(j+1)%3], -2);
Логично, что поверхность стала более гладкой:

А теперь ещё в сто раз сильнее:

Что это? Представьте, что мы обмакнули проволочное кольцо в мыльную воду. В итоге образовавшаяся мыльная плёнка будет стараться иметь наименьшую кривизну, насколько это возможно, касаясь-таки границы - нашего проволочного кольца. Именно это мы и получили, зафиксировав границу и попросив получить гладкую поверхность внутри. Поздравляю вас, мы только что решили уравнение Лапласа с граничными условиями Дирихле. Круто звучит? А на деле всего-навсего одну систему линейных уравнений решить.
Уравнение Пуассона
Давайте ещё крутое имя вспомним.Предположим, что у меня есть такая картинка:

Всем хороша, только стул мне не нравится.
Разрежу картинку пополам:

И выделю руками стул:
Затем всё, что белое в маске, притяну к левой части картинки, а заодно по всей картинке скажу, что разница между двумя соседними пикселями должна равняться разнице между двумя соседними пикселями правой картинки:
For (int i=0; i Вот результат: Код и картинки доступны Одним из методов изучения стохастических связей между признаками является регрессионный анализ .
Наиболее часто для оценки параметров используют метод наименьших квадратов (МНК).
Задача оценивания параметров линейного парного уравнения методом наименьших квадратов
состоит в следующем: получить такие оценки параметров , , при которых сумма квадратов отклонений фактических значений результативного признака - y i от расчетных значений – минимальна.
Проиллюстрируем суть классического метода наименьших квадратов графически
. Для этого построим точечный график по данным наблюдений (x i , y i , i=1;n) в прямоугольной системе координат (такой точечный график называют корреляционным полем). Попытаемся подобрать прямую линию, которая ближе всего расположена к точкам корреляционного поля. Согласно методу наименьших квадратов линия выбирается так, чтобы сумма квадратов расстояний по вертикали между точками корреляционного поля и этой линией была бы минимальной.
Оценка тесноты связи между признаками
осуществляется с помощью коэффициента линейной парной корреляции - r x,y .
Он может быть рассчитан по формуле: Таблица 1
Регрессионный анализ представляет собой вывод уравнения регрессии, с помощью которого находится средняя величина случайной переменной (признака-результата), если величина другой (или других) переменных (признаков-факторов) известна. Он включает следующие этапы:
Наиболее часто для описания статистической связи признаков используется линейная форма. Внимание к линейной связи объясняется четкой экономической интерпретацией ее параметров, ограниченной вариацией переменных и тем, что в большинстве случаев нелинейные формы связи для выполнения расчетов преобразуют (путем логарифмирования или замены переменных) в линейную форму.
В случае линейной парной связи уравнение регрессии примет вид: y i =a+b·x i +u i . Параметры данного уравнения а и b оцениваются по данным статистического наблюдения x и y .
Результатом такой оценки является уравнение:
, где , - оценки параметров a и b , - значение результативного признака (переменной), полученное по уравнению регрессии (расчетное значение).
Метод наименьших квадратов дает наилучшие (состоятельные, эффективные и несмещенные) оценки параметров уравнения регрессии. Но только в том случае, если выполняются определенные предпосылки относительно случайного члена (u) и независимой переменной (x) (см. предпосылки МНК).
Формально критерий МНК
можно записать так:  .
.Классификация методов наименьших квадратов

Математическая запись данной задачи:  .
.
Значения y i и x i =1...n нам известны, это данные наблюдений. В функции S они представляют собой константы. Переменными в данной функции являются искомые оценки параметров - , . Чтобы найти минимум функции 2-ух переменных необходимо вычислить частные производные данной функции по каждому из параметров и приравнять их нулю, т.е. 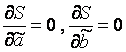 .
.
В результате получим систему из 2-ух нормальных линейных уравнений: 
Решая данную систему, найдем искомые оценки параметров:

Правильность расчета параметров уравнения регрессии может быть проверена сравнением сумм (возможно некоторое расхождение из-за округления расчетов).
Для расчета оценок параметров , можно построить таблицу 1.
Знак коэффициента регрессии b указывает направление связи (если b >0, связь прямая, если b <0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Формально значение параметра а – среднее значение y при х равном нулю. Если признак-фактор не имеет и не может иметь нулевого значения, то вышеуказанная трактовка параметра а не имеет смысла. . Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:
. Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:  .
.
Область допустимых значений линейного коэффициента парной корреляции от –1 до +1. Знак коэффициента корреляции указывает направление связи. Если r x, y >0, то связь прямая; если r x, y <0, то связь обратная.
Если данный коэффициент по модулю близок к единице, то связь между признаками может быть интерпретирована как довольно тесная линейная. Если его модуль равен единице ê r x , y ê =1, то связь между признаками функциональная линейная.
Если признаки х и y линейно независимы, то r x,y близок к 0.
Для расчета r x,y можно использовать также таблицу 1.
Для оценки качества полученного уравнения регрессии рассчитывают теоретический коэффициент детерминации – R 2 yx:
N наблюдения
x i
y i
x i ∙y i
1
x 1
y 1
x 1 ·y 1
2
x 2
y 2
x 2 ·y 2
...
n
x n
y n
x n ·y n
Сумма по столбцу
∑x
∑y
∑x·y
Среднее значение
![]()
![]()
 ,
,
где d 2 – объясненная уравнением регрессии дисперсия y ;
e 2 - остаточная (необъясненная уравнением регрессии) дисперсия y ;
s 2 y - общая (полная) дисперсия y .
Коэффициент детерминации характеризует долю вариации (дисперсии) результативного признака y , объясняемую регрессией (а, следовательно, и фактором х), в общей вариации (дисперсии) y . Коэффициент детерминации R 2 yx принимает значения от 0 до 1. Соответственно величина 1-R 2 yx характеризует долю дисперсии y , вызванную влиянием прочих неучтенных в модели факторов и ошибками спецификации.
При парной линейной регрессии R 2 yx =r 2 yx .


















